



Generative AI (GenAI) dan large language models (LLM) melibatkan algoritma yang mampu menghasilkan konten baru berdasarkan pola yang dipelajari dari data yang ada. Generative AI adalah bentuk AI yang dapat menciptakan konten baru dan orisinal, seperti teks, gambar, audio, video, seni, dan kode. GenAI berlandaskan pada beberapa prinsip teknis, antara lain arsitektur model, pelatihan awal dengan metode self-supervised, dan metode pemodelan generatif.
- Arsitektur model
Berkaitan dengan struktur dan desain dari neural networks yang digunakan untuk menghasilkan konten. Beberapa contoh arsitektur model meliputi transformers, convolutional neural networks, recurrent neural networks, dan mekanisme attention. Pelatihan awal dengan metode self - Supervised
Melibatkan pelatihan model dengan menggunakan sejumlah besar data tanpa label untuk memahami fitur dan pola umum yang nantinya dapat diterapkan pada tugas-tugas tertentu. Beberapa metode pelatihan awal dengan metode self-supervised meliputi masked language modeling, contrastive learning, dan denoising autoencoders. - Metode pemodelan generatif
Teknik dan algoritma yang memungkinkan model untuk memahami distribusi probabilitas dari data dan menghasilkan data baru berdasarkan distribusi tersebut.
Large language models dilatih dengan menggunakan data tanpa label yang sangat banyak, sehingga dapat digunakan untuk berbagai tugas dan disesuaikan sesuai kebutuhan di berbagai sektor. Dengan parameter yang mencapai miliaran, antara 65 miliar hingga 540 miliar untuk model terbaru, model-model ini memerlukan banyak akselerator seperti GPU dan waktu pelatihan yang signifikan. Sebagai contoh, BloombergGPT memerlukan waktu hingga 1,3 juta jam pada GPU untuk pelatihannya.
Salah satu temuan penting dalam penelitian model bahasa adalah bahwa dengan menambah data dan kekuatan komputasi untuk melatih model dengan lebih banyak parameter, kinerja model akan meningkat. Oleh karena itu, jumlah parameter terus meningkat dengan cepat, yang tentunya memberikan tekanan besar pada sumber daya pelatihan. Hal ini menjadikan model yang sudah dilatih sebelumnya menjadi pilihan yang menarik. Model-model yang sudah dilatih, baik yang bersifat open-source maupun komersial, hanya perlu disesuaikan untuk kebutuhan tertentu dan dapat dengan cepat diterapkan untuk inferensi.
Use Cases
Ada beragam aplikasi Generative AI dan LLM yang dapat diilustrasikan, seperti yang ditampilkan pada gambar berikut.
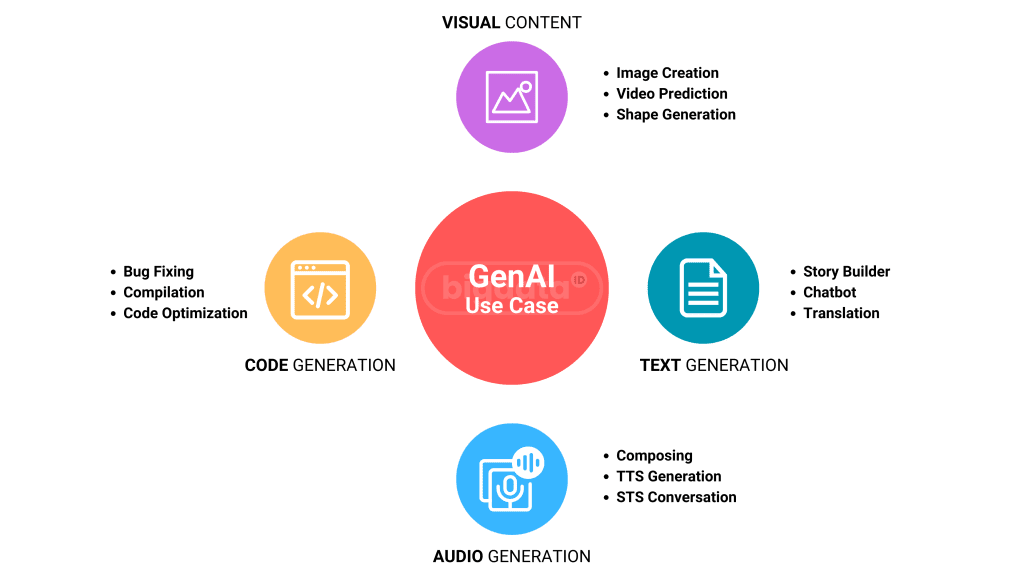
Gambar ini menunjukkan bahwa dengan memulai dari berbagai input seperti audio, video, teks, kode, dan lainnya, keluaran yang ditingkatkan dapat dihasilkan dan dikonversi ke bentuk lain seperti chatbots, terjemahan, kode, avatar, dan sebagainya.
Use case ini dapat diterapkan hampir di semua sektor seperti kesehatan, manufaktur, keuangan, ritel, telekomunikasi, energi, pemerintah, teknologi, dan memberikan dampak bisnis yang signifikan.
Large language models (LLM) dapat menerjemahkan teks ke berbagai bahasa, mengklasifikasikan dan mengatur umpan balik pelanggan untuk pengalaman yang lebih baik, merangkum dokumen legal dan laporan pendapatan, serta menciptakan konten pemasaran yang inovatif. Model seperti ChatGPT, dapat membuat ajakan penjualan, menciptakan salinan iklan, menemukan bug kode komputer, membuat postingan blog, dan menyusun email dukungan pelanggan. Sebagian besar nilai yang diberikan oleh Generative AI terletak pada operasi pelanggan, pemasaran dan penjualan, rekayasa perangkat lunak dan R&D, Life Science, Finance, dan High Tech adalah industri yang diperkirakan akan melihat dampak terbesar berdasarkan pendapatan dengan menggunakan Generative AI.
Pertimbangan Performance
Generative AI dan LLM membutuhkan kapasitas komputasi yang tinggi. Peningkatan signifikan dalam workload performance dan biaya penggunaan sumber daya komputasi dapat diperoleh dengan menggunakan perangkat lunak yang dioptimalkan, libraries, dan frameworks yang memanfaatkan akselerator, paralel operator, dan memaksimalkan penggunaan core. Ada banyak pendekatan yang digunakan untuk mengatasi tantangan ini dari sisi arsitektur transformer, sisi pemodelan, dan pada sisi deployment code.
Arsitektur berbasis transformer menggunakan mekanisme self-attention, yang memungkinkan LLM untuk memahami dan mewakili pola bahasa yang kompleks dengan lebih efektif. Mekanisme ini meningkatkan komputasi yang dapat diparalelkan, mengurangi kompleksitas komputasi dalam sebuah layer, dan mengurangi panjang jalur dalam ketergantungan jarak jauh dari arsitektur transformer.
Untuk pemanfaatan sumber daya yang efisien selama pelatihan dan deployment, pemodelan harus memiliki paralelisme data dan paralelisme model yang sesuai. Pertimbangan algoritmik untuk mempercepat aplikasi dengan pemrosesan paralel terlibat dengan paralelisasi data. Pendekatan ini meningkatkan kinerja dan akurasi, terutama saat menggunakan PyTorch Distributed Data Parallel untuk menyebarkan beban kerja di antara GPU. Paralelisme model dicapai dengan menggunakan teknik checkpointing aktivasi dan akumulasi gradien untuk mengatasi tantangan yang terkait dengan modelbesar memory footprint.
Dalam aspek deployment code, tantangan utamanya adalah bandwidth, terutama saat memindahkan bobot dan data antara unit komputasi dan memori. Unit komputasi (CU) adalah kumpulan unit eksekusi pada unit pemrosesan grafik (GPU) yang dapat melakukan operasi matematika secara paralel. Mengoptimalkan penggunaan unit komputasi dan memori diperlukan untuk menjalankan model ini dengan efisien, cepat, dan memaksimalkan kinerja.
Arsitektur jaringan yang kompleks, menantang deployment real-time yang efisien dan memerlukan sumber daya komputasi yang signifikan dan biaya energi. Tantangan ini dapat diatasi melalui optimalisasi seperti neural network compression. Ada dua jenis kompresi jaringan: pemangkasan (pruning) dan kuantisasi (quantization). Ada berbagai metode untuk melakukan pemangkasan, yang tujuannya adalah untuk menghilangkan komputasi yang berlebihan. Kuantisasi mengurangi presisi dari jenis data untuk mencapai pengurangan dalam komputasi. Untuk arsitektur model ini, bilangan bulat 8-bit biasanya digunakan untuk bobot, bias, dan aktivasi.
Campuran yang presisi dapat meningkatkan kecepatan dengan tujuan mengelola presisi dengan cerdas sambil mempertahankan akurasi dan mendapatkan kinerja dari format numerik yang lebih kecil dan lebih cepat.
Kesimpulan
Generative AI (GenAI) dan Large Language Models (LLM) telah mengubah cara kita memahami dan menerapkan kecerdasan buatan, dengan kemampuan unik mereka untuk menghasilkan konten orisinal berdasarkan data yang ada. Mereka tidak hanya memfasilitasi penciptaan konten dalam berbagai format seperti teks, gambar, dan audio, tetapi juga menawarkan solusi inovatif untuk berbagai sektor industri, mulai dari kesehatan hingga teknologi. Meskipun potensinya luar biasa, implementasinya penuh dengan tantangan, terutama dalam hal kebutuhan komputasi. Oleh karena itu, optimalisasi dalam pelatihan dan deployment menjadi esensial, memerlukan pendekatan teknis yang canggih untuk memastikan efisiensi dan kinerja yang maksimal.
Glosari
- Akselerator: Perangkat keras yang mempercepat beberapa fungsi komputasi tertentu, seperti pemrosesan grafik (GPU).
- Arsitektur Model: Struktur dan desain dari neural networks yang digunakan untuk menghasilkan konten. Termasuk transformers, convolutional neural networks, recurrent neural networks, dan mekanisme attention.
- Attention: Mekanisme yang memungkinkan model untuk fokus pada bagian tertentu dari input saat menghasilkan output.
- Bandwidth: Kapasitas transmisi data melalui jalur komunikasi dalam waktu tertentu.
- Checkpointing Aktivasi: Teknik yang digunakan untuk menyimpan status dari aktivasi dalam model selama pelatihan, membantu dalam mengatasi masalah memori.
- Convolutional Neural Networks (CNN): Jenis jaringan saraf yang khusus dirancang untuk pengenalan pola dan biasanya digunakan dalam pengolahan gambar.
- Contrastive Learning: Teknik pelatihan tanpa pengawasan di mana model belajar untuk mengidentifikasi kemiripan dan perbedaan antara pasangan data.
- Denoising Autoencoders: Jenis jaringan saraf yang dilatih untuk merekonstruksi input setelah menghapus sebagian informasi dari input tersebut.
- Generative AI (GenAI): Bentuk kecerdasan buatan yang dapat menciptakan konten baru dan orisinal.
- Large Language Models (LLM): Model bahasa dengan parameter yang mencapai miliaran, yang dilatih dengan data tanpa label dalam jumlah besar.
- Masked Language Modeling: Metode pelatihan di mana beberapa kata dalam teks masukan disembunyikan dan model berusaha menebaknya.
- Metode Pemodelan Generatif: Teknik dan algoritma yang memungkinkan model untuk memahami distribusi probabilitas dari data dan menghasilkan data baru berdasarkan distribusi tersebut.
- Neural Network Compression: Teknik untuk mengurangi ukuran dan kompleksitas model neural network.
- Paralel Operator: Teknik yang memungkinkan operasi untuk dijalankan secara bersamaan, meningkatkan kecepatan pemrosesan.
- Pelatihan Awal dengan Metode Self-Supervised: Pelatihan model dengan menggunakan data tanpa label untuk memahami fitur dan pola umum.
- PyTorch Distributed Data Parallel: Alat dalam PyTorch yang memungkinkan pelatihan model secara paralel di beberapa GPU.
- Quantization (Kuantisasi): Mengurangi presisi dari jenis data untuk mencapai pengurangan dalam komputasi.
- Recurrent Neural Networks (RNN): Jenis jaringan saraf yang dirancang untuk mengenali pola dalam urutan data.
- Self-Attention: Mekanisme di dalam arsitektur transformer yang memungkinkan model untuk memberi bobot pada bagian tertentu dari input.
- Transformers: Jenis arsitektur model yang menggunakan mekanisme attention untuk meningkatkan pemahaman konteks dalam data.
- Unit Komputasi (CU): Kumpulan unit eksekusi pada GPU yang dapat melakukan operasi matematika secara paralel.







